The something.com Voyage: Tracing the Steps from Browser Input to Web Output

A dumb AI Engineer.
Ever wondered that when you enter some URL, maybe google.com or hashnode.com or maybe musaaib.hashnode.dev 😉, what happens behind the scenes? Considering the time it takes to load, some Genie silently reshuffles the deck of the pages in his giant hand and quickly inserts them into my laptop, maybe through some port or directly into my router, which sends it back to my laptop. Sound interesting, right? There's a small problem here, geeks. Neither my laptop, nor my router was a part of of that movie, not even musaaib.hasnode.dev. Does that mean we're in trouble. I'd say, No, not at all. We were in the world of imagination. So, we need to move into our world, the tech world and see what happens behind the scenes. So, let's bid adieu to our Genie and get started. Ba-Bye Genie
So, people, what do you think happens when we browse something on the internet. How many processes come into play? How many things are looked up? Does our request directly go to the server of our something.com or something.xyz. Let's dive into a not so simple diagram that would either clear our concept or drive us crazy.
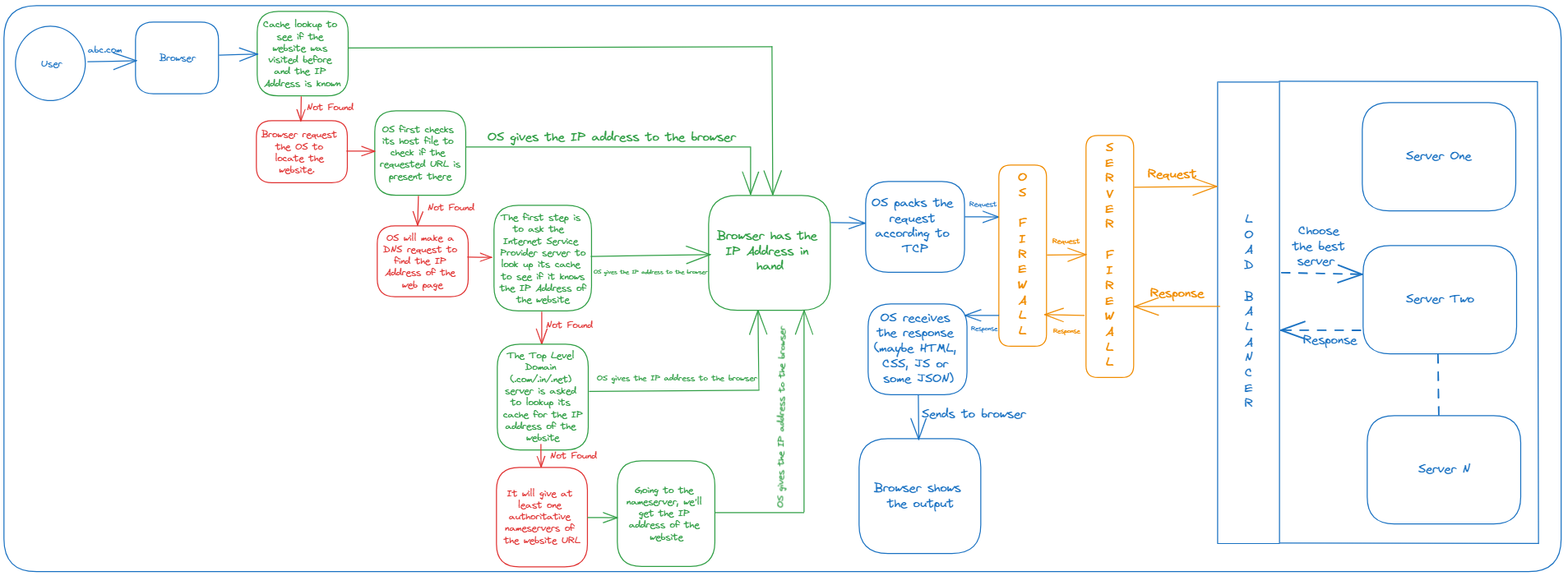
I know some geeks would have expected very less number of boxes and requests, even I had before studying it in detail. Now, let's make it super-easy for everyone to understand the whole cycle in great detail using simple examples as always.
When I open a browser and enter a URL, let suppose musaaib.hasnode.dev again, it's something that the world of web doesn't understand, just like I don't understand Spanish or German. It's just like that I order something from a restaurant (on call), where the support staff just understands Urdu, but I tell them the address in English. The first and foremost job for the staff is to get the address translated. Same goes for our case. The browser needs to translate the domain name to an IP address. So, the browser would first lookup in its own cache, yes, browser has a cache of its own. It checks if the website was visited before and if it has the IP address of the website.
If it's not found in the browser cache, the browser requests the Operating System to locate the website. This sounds a bit new, right. How does the OS know about it? OS has a file known as Hosts File.
Host(s) File
Hosts file, is a plain-text file on a computer's operating system that maps hostnames to IP addresses. It is used as a local DNS (Domain Name System) resolver. When you enter a URL into your web browser, the operating system checks the host file first to see if it has an entry for that particular domain.If it's present, it will give the browser the IP address found and if not found, the OS itself would make a DNS (Domain Name Service) request in order to find the IP Address of the website.
First, the ISP (Internet Service Provider) is requested, which looks up in its cache to find if it has the IP address of the website. If found, it'd send the address to the OS, which would give it to the browser for further processing.
If the ISP isn't able to find the requested domain in its cache, it proceeds to ask the root DNS server. The root server then directs the query to the Top-Level Domain (TLD) server associated with the TLD of the requested domain to look in its cache. For example, our domain is a .dev domain, the query goes to the .dev TLD server to lookup in its cache for the IP address. If found, it'd send the address to the ISP, which then sends to the OS, which would give it to the browser for further processing.
If not found in the TLD cache, the TLD would have an authoritative nameserver associated with the given URL. The TLD server doesn't manage individual domain names; instead, it points to the authoritative nameserver for the specific domain. In the case of a .dev domain, it would direct the query to the authoritative nameserver that manages the domain names and their corresponding IP addresses within the .dev TLD.
Going to the nameserver would definitely give the IP address of the URL, provided it is a correct one, which would be sent to the OS, which, in turn, sends it to the browser.
Finally, our browser has the IP address in hand now. Now the restaurant knows where to deliver its order. They might have taken them 5-10 minutes to translate, but in our case, this is done in fractions of a second. Interesting, right?
Now starts the actual process towards the webserver. The browser sends a request to the IP address we just fetched, but the browser requests the OS, which packs the request as per the Transmission Control Protocol.
The request also goes through the firewalls imposed by the OS and the server as well to ensure that the request has no security violations.
Then the request is received by a Load Balancer. The load balancer receives incoming requests from clients and distributes them across the available servers based on a predefined algorithm (e.g., round-robin, least connections, etc.). So, it directs the request to one of the web servers handling the website. Each server processes the assigned request independently and generates a response.
The servers send their responses back to the load balancer. The load balancer, upon receiving the responses, may perform additional processing or make decisions based on its configuration. For example, it might aggregate or modify the responses, check for server health, or apply additional load balancing logic.
Finally, the load balancer sends the aggregated or modified responses (if any) back to the original client that made the request.
Now, the OS receives the response. It might be a webpage consisting of (HTML, CSS and JS) or maybe some JSON data. The OS gives the data to the browser, which interprets it and shows us the information.
Guess, what. All this happens in seconds or even fractions of a second, if we have a good internet connection.
In conclusion, the journey from entering a domain name in your browser to accessing a webpage is a complex yet seamless process orchestrated by the Domain Name System (DNS). From local cache checks to interactions with root servers, TLD servers, and authoritative name servers, each step plays a crucial role in translating human-readable domain names into machine-readable IP addresses. As we navigate the vast landscape of the internet, it's fascinating to recognize the intricate mechanisms behind the scenes that enable the swift and reliable retrieval of information. The DNS, with its hierarchical structure and distributed network of servers, stands as a foundational pillar, ensuring the seamless connectivity that we often take for granted in our daily online experiences.
Keep Learning, Keep Growing, Keep Browsing!
Would love to hear your feedback on this.
I'm immensely grateful to takeUforward (https://takeuforward.org) for their System Design Playlist, which serves as a great source of knowledge. The playlist helped me understand this topic, which is the reason that I could write it down.
Peace, Dot!



